 |
Subscribe via Email |
 |
|
|
|
Connectors are the heart and soul of Federated Search (FS)
engines and with the rise in importance of FS in today’s fast paced, Big Data,
analyze everything world, they are crucial to smooth and efficient data
virtualization and flow. MuseGlobal
has been building Connectors, and the architecture to use them (the Muse/ICE
platform) and maintain and support them (the Muse Source Factory) for over 12
years. The people who design and build Connectors must be both computer savvy,
and also have a deep understanding of data and information and its myriad
formulations.
This second in the series of posts looks at the problems
arising as data is needed from outside the enterprise, and the complexities of
access and extraction that result. Not surprisingly, as a leading FS platform
Muse and its ecosystem are in the forefront of providing solutions to data
complexity problems in the modern world. (The first post considers the growing
importance of being able to access data from inside an organization.)
Part 2 A
broader perspective
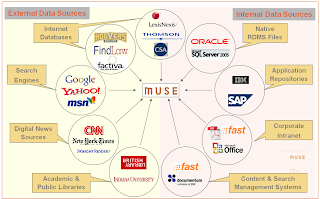 All of this speaks to the volume and velocity (of change)
of the data – two of the trio of defining “v”s of Big Data. The third v is
variety and this is now encompassing much more than the internal data silos of
the enterprise. Increasingly decisions need to take account of the outside
world: competitors, news media, commentators and analysts, customer feedback,
social postings and tweets.
Most of these sources are also fleeting. Customer records
will last for years, a tweet is gone in 9 days. Even product reviews are only
relevant until the next version of the product is released. And there are
another couple of additional hurdles to jump to get this valuable “perspective”
data.
This data lives outside the enterprise. Some other person
or organization has control of it. And that means the old ETL trick of grabbing
everything is likely to be severely frowned on – especially if it is tried
every night. Commercial considerations mean that, if this data is valuable to
you, then it is valuable to others, and the owners will not let you have it all
for free. This means the strategy of asking for exactly what is needed is the
way to go. It takes less time everywhere, will cost less in processing and
transmission, will cost less in data license fees, and will not alienate
valuable data sources. So “sipping gently” is the way to go.
Yes, in the paragraph above you saw “fees” mentioned.
Once the commercial details have been sorted out, there is still the tricky
technical matter of getting access through the paywall to the data you need,
and are entitled to. Some services will provide some of the data you want for
free, but most will require authenticated access even of there is no charge
Those who are selling their data will certainly want to know that you are a
legitimate user, and be sure you are getting what you have paid for – and no
more.
For both of these considerations Federated Search
engines, especially in their harvesting mode allow all the “virtual data” to
become yours when you need it. Access control is one of the mainstays of the
better FS systems to ensure just this fair use of data. And gentle sipping for
just the required data is their whole purpose. Again a tool for the task
arises. MuseGlobal runs a Content Partner Program to ensure we deal fairly and
accurately with the data we retrieve from the thousands of sources we can
connect to, both technically and as a matter of respecting the contractual
relationship between the provider and consumer. We are the Switzerland of data
access – totally neutral and scrupulously fair, and secure.
Complexity everywhere
So now you are accessing internal and external data for
your BI reports. Unfortunately, while you might have a nice clean Master Data Managed
situation in your company, it is not the one the external data sources are
using (not unless you are Walmart or GM and can impose your will on your
suppliers, that is). And this means the analysis will be pretty bad unless you
can get internal product codes to match to popular names in posts and tweets.
There is a world of semantic hurt lurking here.
You need tools. Fortunately the Federated Search engine
you are now employing to gather your virtual data is able to help. Data
re-formatting, field level semantics, content level semantics, controlled
ontologies, normalized forms, content merging and de-merging, enumeration,
duplicate control, all these are tools within the FS system. They are powerful
tools and they are very precise, and they come with a health warning: “This
Connector is for use with this source only”.
Connectors are built, and maintained, very specifically
for a single Target. They know all about that target, from its communications
protocol to the abbreviations it uses in the data. Thus they produce the
deepest possible data extraction possible. And can deliver that data in a
consistent format suited to the Data Model and systems which are going to use
it. They are data transformers extraordinaire. This contrasts with crawlers at
the other end of the scale where the aim is to get a simple sufficiency of data
to handle keyword indexing.
This precision means that they are in need of “tuning”
whenever their target changes in some way. Major changes like access protocols
are rare, but a website changing the layout of its reviews is common and
frequent. Complexity like this is handled by a “tools infrastructure” for the
FS engine whereby testing, modification, testing again, and deployment are
highly automated actions, reducing the human input to the problem solving, not
the rote.
And now another wrinkle: some of the data needed for the
analysis is not contained in the records you retrieve, and the only way to
determine this is to examine those records and then go and get it. As a simple
example think of a tweet which references a blog post. The tweet has the link,
but not the content of the post. For a meaningful analysis, you need that
original post. Fortunately the better FS systems have a feature called
enhancement which allows for just this possibility. It allows the system to
build completely virtual records from the content of others. Think more deeply
of a hospital patient record. This will have administrative details, but no
financial data, no medical history notes, not results of blood tests, no scans,
no operation reports, no list of past and current drugs. And even if you gather
all this, the list of drugs will not include their interactions, so there could
be more digging to do. A properly configured and authenticated FS system will
deliver this complete record.
Analysis these days is more than just a list of what
people said about your product. It involves demographics and sentiment, and timeliness
and location. All these can come from a good analysis engine – if it has the
raw data to work from. Enhanced virtual records from a wide spectrum of sources
will give a lot, but making the connections may not be that simple. We
mentioned above “official” and popular product names and the need to reconcile
them. Think for a moment of drug names. Fortunately a good FS system can do a
lot of this thinking for you, and your analytics engine. Extraction of entities
by mining the unstructured text of reviews and posts and news article and
scientific literature allows them to be tagged so that the analysis recognizes
the sameness of them. Good FS engines will allow this to a degree. Better ones
will also allow that a specialist text miner can be incorporated in the
workflow and give each record its special treatment – all invisibly to the BI
system asking for the data.
Partnership at last
There is a lot of data out there, and a great deal of it
is probably very useful to you and your company. Using the correct analysis
engines and Federated Search “feeding” tools enables that data to be brought
together in a flexible, efficient, and accurate manner to give the information
needed for informed decisions.
Federated Search is still a very powerful and effective
way to search for humans, but it has grown up to be one of the most effective
tools for systems integration, the breaking down of corporate silos of data,
and the incorporation of data from the whole Internet into a unified, useable
data set to create real knowledge.
Muse is one of those tools which can supply the complete
range from end user fed search portals, to embedded data virtualization, and we
intend to keep up with the next turn of data events.
 Connectors are the heart and soul of Federated Search (FS)
engines and with the rise in importance of FS in today’s fast paced, Big Data,
analyze everything world, they are crucial to smooth and efficient data
virtualization and flow. MuseGlobal
has been building Connectors, and the architecture to use them (the Muse/ICE
platform) and maintain and support them (the Muse Source Factory) for over 12
years. The people who design and build Connectors must have rich technical
expertise, and also have a deep understanding of data and information and its
myriad formulations.
This series of posts will look at the problems arising as
data grew in volume, spread across systems, moved outside the enterprise, and
became all important for the business intelligence which informs current
corporate decisions. Not surprisingly, as a leading FS platform Muse and its
ecosystem are in the forefront of providing solutions to data problems in the
modern world.
This first post considers the growing importance of being
able to access data from inside an organization. (The second post looks at the
problems arising as data is needed from outside the enterprise, and the
complexities of access and extraction that result.)
Part 1 Wanted:
data from over there, over here
As the world of Big Data grows daily and the
importance of unstructured data becomes more evident to information workers and
managers everywhere, methods of accessing that data become critical to success.
Typically in an enterprise the majority of their data is
held in relational DBMS’s which are attached to the transaction systems that
generate and use it. These include HR, Bill of Materials, Asset Management
systems and the like. However for
managers to make strategic decisions on even this data is difficult, they need
to see it all at once. The analysis managers need is performed by a Business
Intelligence (BI) system, and it works on data held in its own (OLAP) database,
which is specially structured to give quick answers to pre-formulated
questions.
And here is the first problem: transaction systems with
lots of data, and an analysis system with an empty database. The solution: set up and run a batch process
for each working database that takes a snapshot of its data and transforms and
loads it into the OLAP database. This is ETL (Extract, Transform, Load) and is
where most big company systems are at the moment. The transaction systems have
no method of exporting the data, and the analysis engine just works from what
it has. This three part solution works and it works well, but it has some
problems.
Running a snapshot ETL on each working system at
“midnight” obviously takes time, and can be nearly a day old before the process
starts. This lack of “freshness” of the data didn’t matter too much 5 or even 2
years ago. It took so long to change systems as a result of the analysis that
data a day or so old was not on the critical path. But today’s systems can
adapt much more rapidly, and business decisions need to be based on hourly or
even by-the-minute data. (Of course, if you are in the stock and financial
markets then your timescale is down to micro-seconds, and you have specialist
systems tailored for that level of response.) So first we need to improve on our timing.
In order to do that we need to move from a just-in-case
operation to a just-in-time one. Rather than collect all the data once a day,
we need to be able to gather it exactly when we need it. Of course gathering it
overnight as historic data is still important and makes the whole process work
more smoothly and quickly as the just-in-time data is now only a few hour’s
worth and so can be processed that much quicker to get it into the BI system.
Now we have a two-legged approach: batch bulk and focused immediate updates.
Sounds good, but the ETL software for the batch work will not handle the real
time nature of the j-i-t data requests.
For a start the ETL process grabs everything in the
transaction system database – all customers, all products, all markets. But a
manager is generally going to ask for a report on a specific customer or
product. It would be endlessly wasteful to grab all that “fresh” data for all
customers, when only data for one is needed. So the j-i-t process has to be
able to query the transaction system, rather than sweep up everything. It is
also almost certain that the required report will need data from more than one
transaction system, but probably not all of them. ETL is not set up to do this;
it needs a system capable of directing queries at designated systems and
transforming those results. And, finally, the extracted data may well need to
be in a different format. After all now we are loading the data directly into
the Business Intelligence analysis engine for this report (for speed), and not
importing it to the OLAP database. This
means that the structure and semantics are all different.
Increasingly the tools of choice for these j-i-t
operations are Federated Search (FS) systems such as MuseGlobal’s Muse platform.
They can search a designated set of sources (transaction systems), run a
specific query against them, and then re-format the results and send them
directly to the analysis engine. Initial examples of FS systems are user
driven, but for this data integration purpose, the more sophisticated FS
systems are able to accept command strings and messages in a wide variety of
protocols, formats and languages and act on them, thus allowing the FS system
to act a s a middleman getting the data the BI engine needs exactly when it
needs it. Muse, for example, through its use of “Bridges” can accept command
inputs in over a dozen distinctly different protocols, and can query all the
major enterprise management suites in a native or standards-based protocol.
Should we move?
The need for speed of analysis and the volume of data
involved grows every day it seems. It takes time to extract all that data and to
build a big OLAP database just in case we want it. What’s more, building, and changing the
structure to adapt to changing analysis needs takes time – a lot of it.
So modern BI systems have moved to holding their database
in memory, rather than on disk, just so everything is that much faster. Modern
analysis engines, many based on the Apache project’s Hadoop engine, can handle a lot of data in
a big computer, and do it rapidly. Both Oracle ( Exalytics)
and SAP ( Hana)
have introduced these combined in-memory database plus analytics engine, and
others are coming. (See here
for an InformationWeek take on the war of words surrounding them.) These
engines can be rapidly configured (often in real time, through a dashboard) to
give a new analysis report – as long as they have the data!
Moving all that data from the transaction system takes
time, so the current mode is to leave it there and rely on real-time
acquisition of what is needed. This is of course much less disruptive, fresher,
and much more focused on the analysis at hand. This is not to say that
historical data is not important; it is, and it is used by these engines, but
the emphasis is more and more on that last bar on the graph.
So, again we need a delivery engine to get our data for
us from all the corporate data silos, get it when it is needed, and then deliver
it to the maw of the BI analytics engine. Once again the systems integration,
dynamic configuration and deep extraction technologies of a Federated Search
engine come to the rescue. Muse supports the real time capabilities, parallel
processing architecture, session management, and protocol flexibility to
deliver large quantities of data when asked for, or on a continuing “feed”
basis.
The world of independent Federated Search is diminishing;
last week IBM announced that they will be acquiring Vivisimo.[1] There are a number of interesting aspects to
this, and the analysts have covered some of them [2],[3], but some particular quotes
from IBM itself and the analysts piqued my interest:
“The
combination of IBM's big data analytics capabilities with Vivisimo software
will further IBM's efforts to automate the flow of data into business analytics
applications …” [IBM]
“IBM also
intends to use Vivisimo's technology to help fuel the learning process for
their Watson
applications.” [IDC]
“Overall,
this is a very smart move for IBM, and it indicates that unstructured
information is going to play an increasingly
large role in the Big Data story…” [IDC]
All this shows the handling of structured and
unstructured information growing in importance.
What does IBM want Vivisimo for? It seems to all stem
round Big Data and the analytics that it can produce to enable better corporate
decisions. Of course, there’s also the
lovely teaser of a better performing Watson! Both Watson and Analytics massage
vast amounts of data and information to draw conclusions, assign values, and
create relationships. But, like all such endeavors, the quality of the result
depends critically on the quality of the incoming data. GIGO says it all!
Big Data analytics work very well with structured data,
where the “meaning” of each number or term is exactly known and can be
algorithmically combined with its peers, parents, siblings, and opposites to
give a visualization of the state of play at the moment or over time. Gathering
such data is a tedious process (hooray for computers!), but is not
intrinsically difficult. All that needs to happen is to set up a mapping from
each data Source to the master and let it run. The mappings are precise and the
process effective, but the volumes are vast and the time-to-repeat rather slow
for today’s fast paced world.
However, now add the fact that not everything you want to
know is held in those nice regular relational database tables, and the picture
looks far less rosy. Product reviews are unstructured, press releases are
vague, social comments are fleeting, and technical and legal documents tend to
be obtuse. But all these are vital if you want to make a really informed
decision. So bring in Federated Search to the rescue.
Federated Search is a real time activity. It is focused
on just what data or information is needed now. And it provides quality data.
It is directed to just those Sources needed for “this report”, and it analyzes
them in terms of known semantics so that the reviews, blogs, etc. mesh with the
numerical analytics, and then provide the essential “external view” of the situation.
And this is done right now, in real time. For the knowledge based systems (like
Watson) the FS Sources provide in-depth data pertinent to the current problem.
And if the Sources don’t have it, FS goes and finds it, thus allowing Watson (as an example) to add it to its knowledge base, and provide a
more informed opinion.
So that is why IBM is adding Federated Search to its
armory. What are the issues? In a word (or two): coverage and completeness.
All the Big Data systems use standardized access to the
massive databases of the corporation’s transaction and repository systems. Most
of these understand SQL or some other standard access language, and the
customization is a matter of reading a schema mapping table. That mapping table
is the same for every SharePoint or Exchange system (or similar), so once
created, it is easily deployed. These types of standardized accesses are often
referred to as “Indexing Connectors” because they extract enough data to enable
the content to be indexed and searched. (For more on this see a future post on
the deep differences between Connectors and Crawlers.)
Now, move to the world of web data and the complexity and
difficulty escalates enormously. The number
of formats and access methods multiplies almost to the point of one-to-one for
each Source. As an example look at the two press releases for this acquisition:
IBM’s is a press release, with an initial dateline, and no tags, Vivisimo’s [4]
is a blog post with tags and an author. The same Connector will not make sense
of both at the level of detail needed for a decision making analysis.
Add in the velocity of the data in the social media
(“velocity”, as you will recall, is one of the 3 “v”s that define Big Data –
Volume, Variety, Velocity) and the relatively slow to aggregate times of
conventional databases become a problem. Timing is an issue because of volume,
but also because applications have to analyze input data from users and other
sources, store it in their transactional database, and then the ETL function
has to extract from that database and move the data to the analytics database
or storage area. These are two stages, both relatively slow, that must be
batched together.
So, once moving from structured data to unstructured data,
and from the sheltered waters of the corporation to the rough seas of the Web,
a very different set of techniques is needed. And that is where Federated
Search (FS) comes in. This is the truly
hard, difficult part, and it’s where MuseGlobal shines. But first, some more information on what FS
is, and what it needs to do.
FS is immediate, which involves many synchronization and
“freshness” issues, but essentially solves the “velocity” problem by obtaining
data as it is needed. That is because FS is a “on demand” service. It is
brought into play just-in-time to get the data when needed, not in batch mode
to store it away just-in-case. Since it is used when needed it needs to be able
to target the Sources of interest right now. That means it is flexible and
dynamically configured, not painstakingly set up ahead of time and left alone.
Since it is a focused operation, targeting only the data
needed, it must be able to get the maximum out of each Source. This requires
two levels of complexity not common in other types of connectors or crawlers. These
Sources have specific protocols and search languages and often security
requirements. All these must be handled by the FS Connector so that the search
is faithfully translated to the language of the Source, and the results are
accurately retrieved. Second is getting the retrieved data into a useable form
(and format). This involves a “deep extract” involving record formats,
field/tag/schema semantics, content semantics, data normalization and
cleansing, reference to ontologies, field splitting, field combination, entity
extraction on rules and vocabularies, conversion to standard forms, enhancement
with data from third Sources, and other manipulations. None of this is
off-the-shelf processing where a single connector can be parameterized to work
with all Sources. So FS has started at the “single, deep” end of the spectrum
(crawlers are the epitome of the “broad, shallow” end) and builds Connectors to
the characteristics of each Source.
These Connectors bring focused, quality data, but they
come at a price. Vivisimo and MuseGlobal, and the other FS vendors build a very
special type of software – something that we know will eventually fail, when
the characteristics of the Source change. This needs a special dynamic
architecture to accommodate it. It needs very powerful ways to build Connectors
which can involve data analysts and programmers, as well as highly
sophisticated tools, such as the Muse Connector Builder. It needs a robust and
automated way to check for end-of-life situations, such as the Muse Source
Checker, and a highly automated build and deploy process – the Muse Source
Factory has been delivering automated software updates for 11 years now. Source
Connectors *will* stop working, and a big part of a viable FS ecosystem is
being able to get them back on line quickly and reliably. MuseGlobal has put together a data
virtualization platform with thousands of Connectors, because we know there’s a
one-on-one relationship with each data source if you want to connect to the
world out there. Figuring out the
unstructured data problem was one of our main goals at Muse from the very
beginning, some 11 years ago.
Of course, building Connectors in the first place is an equal
challenge, including the human element of dealing with a multitude of companies
publishing information and data. This is something all FS vendors have to
handle, and MuseGlobal chose to create a Content Partner Program about 10 years
ago where we talk regularly to hundreds of major Sources and content vendors.
Breadth of coverage of the Connector library is a major factor in “getting up
and running” time, and a major investment for the FS vendors. We believe that
Muse has one of the largest libraries with over 6,000 Source specific
Connectors, as well as all the standard API and protocol and search languages
ones for access where that is appropriate – but still with the “deep
extraction” which is the hallmark of Federated Search.
It is not an easy task to get right at a quality and
sustainable level, but a few vendors have produced the technology. MuseGlobal
is one – and Vivisimo is another.
IBM Analytics and Watson are set for a real quality
revolution!
Another analyst 's comments can be found on enterprise search blog at [6].
(*) You will need to be a subscriber to see the report
 Today's eWeek online version, 2012-02-20, contains a story, Cloud Computing and Data Integration: 10 Trends to Watch, within its "Cloud" section seemingly written around the capabilities of Muse. Or, perhaps MuseGlobal has been developing capabilities within its flagship software platform which fit the "waves of the future" now starting to break on the shore of today's business needs. Today's eWeek online version, 2012-02-20, contains a story, Cloud Computing and Data Integration: 10 Trends to Watch, within its "Cloud" section seemingly written around the capabilities of Muse. Or, perhaps MuseGlobal has been developing capabilities within its flagship software platform which fit the "waves of the future" now starting to break on the shore of today's business needs.
The story is one of the familiar 10 slide shows in which they distill the wisdom of their in-house experts and those of external tech watchers – in this case some Gartner – and an interested developer, to gaze into a particular tech crystal ball. This one is focused on business needs and the cloud. In their own words:
Increasingly, large organizations are discovering and using enterprise information with the objective of growing or transforming their business as they seek more holistic approaches to their data integration and data management practices. This is all in an effort to address the challenges associated with the growing volume, variety, velocity and complexity of information. ... intensifying expectations for cloud data integration and data management as a part of a company's information infrastructure. ... to enable a more agile, quicker and more cost-effective response to business needs. ...eWEEK spoke to Robert Fox, of Liaison Technologies.
So what are the trends (details in the eWeek article)? And how does Muse fit in those trends?
EAI in the Cloud
Muse provides a cloud based service enabling standards based systems and those with proprietary messaging protocols to communicate with each other. This is a hub-and-spoke architecture, so once an application has its Connector written, it can communicate with ALL the other applications working with that Muse hub.
B2C Will Drive B2B Agility
Not so obvious here, but Muse has Connectors for access to the major, and quite a few minor, social platforms, so including their information and practices in the B2B world should be that much easier.
Data as a Service in the Cloud
Where service providers gather information and data from disparate sources, merge it, de-dupe it, cleanse it, and hand it on the service user, Muse is an obvious platform with all of these capabilities baked in from the first batch. Increasing numbers of data providers and the rise of the data brokers, means Muse has a niche as the functional platform for these new providers.
Integration Platform as a Service
"Integration platform as a service (iPaaS) allows companies to create data transformation and translation in the cloud ..." I couldn't have put it closer to the core of what Muse does, if I had said it myself!
Master Data Management in the Cloud
Aggregation, de-duplication, transformation, normalization, conformance to standards (local and International), consistency, identification of differences, enrichment, delivery – this could again be a description of a Muse harvesting service. Right here when needed.
Data Governance in the Cloud
Not directly a Muse function, but its transaction and processing logs make provenance and quality of data easier to report on and find the areas of weakness.
Data Security in the Cloud
Secure communications, a sophisticated range of authentication options, encryption when needed, and NO intermediate storage of the data means that Muse as a transaction service is not the weak security link in the chain.
Business Process Modeling in the Cloud
Not a core strength of Muse – can't win them all. But complex data manipulation processes can be handled through scripting within Muse. Connection to and from external service platforms means that they can be allowed to control the modeling and allow Muse to deal with the data.
Business Activity Monitoring in the Cloud
Tie Muse's aggregation and data cleansing to a link with your favorite BI service and monitoring became rather easier. Because Muse links to systems, it will work with virtually any BI system and place the raw data and analyses wherever they are needed for review.
Cloud Services Brokerage
If this sounds like your business (or one you want to get into), then a look at the Muse platform could save a lot of time and effort to get a superior service up and running. As the technology behind a CSB it takes some beating!
So how did Muse do? Seven right on the money and three near misses seems like a pretty high score to us.
|
 All of this speaks to the volume and velocity (of change)
of the data – two of the trio of defining “v”s of Big Data. The third v is
variety and this is now encompassing much more than the internal data silos of
the enterprise. Increasingly decisions need to take account of the outside
world: competitors, news media, commentators and analysts, customer feedback,
social postings and tweets.
All of this speaks to the volume and velocity (of change)
of the data – two of the trio of defining “v”s of Big Data. The third v is
variety and this is now encompassing much more than the internal data silos of
the enterprise. Increasingly decisions need to take account of the outside
world: competitors, news media, commentators and analysts, customer feedback,
social postings and tweets.
